C++ - regex e iteratori
Table of Contents
Introduzione
Le espressioni regolari, chiamate anche regex (dall'inglese regular expressions), sono sequenze di caratteri che definiscono un pattern di corrispondenza. Le espressioni regolari sono ampiamente utilizzate per la ricerca e la manipolazione di testi basati su determinati criteri di corrispondenza.
Le espressioni regolari sono costituite da una combinazione di caratteri normali (come lettere, numeri e simboli) e caratteri speciali, noti come metacaratteri, che hanno significati speciali nel contesto delle espressioni regolari. Ecco alcuni metacaratteri comuni:
- . (punto): Corrisponde a qualsiasi singolo carattere, ad eccezione di un carattere di nuova riga.
- * (asterisco): Corrisponde a zero o più occorrenze del carattere o del gruppo precedente.
- + (più): Corrisponde a una o più occorrenze del carattere o del gruppo precedente.
- ? (punto interrogativo): Corrisponde a zero o una sola occorrenza del carattere o del gruppo precedente.
- [] (parentesi quadrate): Specifica un insieme di caratteri possibili. Ad esempio, [abc] corrisponde a a, b o c.
- () (parentesi tonde): Raggruppa un insieme di caratteri o metacaratteri per formare un'unità.
- \ (barra rovesciata): Utilizzato per "scappare" un metacarattere, rendendolo un carattere normale. Ad esempio, \. corrisponde al carattere di punto reale invece che al metacarattere ..
- $ La struttura è collocata alla fine della frase |
- ^ La struttura è collocata all'inizio della frase |
Oltre a questi metacaratteri di base, ci sono molti altri metacaratteri e costrutti che consentono di specificare criteri di corrispondenza più complessi. Alcuni esempi includono:
- \d: Corrisponde a un carattere numerico.
- \w: Corrisponde a un carattere alfanumerico o al carattere di sottolineatura _.
- \s: Corrisponde a un carattere di spazio bianco (spazio, tabulazione, ritorno a capo, ecc.).
- | (pipe): Indica una scelta tra due opzioni. Ad esempio, a|b corrisponde a a o b.
Le espressioni regolari possono essere utilizzate in molti contesti, come la ricerca di corrispondenze in una stringa, la sostituzione di porzioni di testo, la validazione delle stringhe, il parsing dei dati e molto altro ancora. Nelle implementazioni di C++, puoi utilizzare la libreria <regex> per lavorare con le espressioni regolari e utilizzare le funzionalità correlate.
Ad esempio per descrive la struttura di un indirizzo email possiamo utilizzare il seguente costrutto
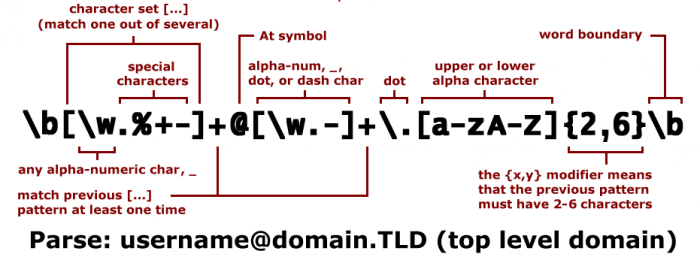
Figure 1: Costrutto descrittivo di un indirizzo email
Cose che si ripetono
Il fatto di essere capaci di individuare di caratteri variabili è la prima cosa che le espressioni regolari possono fare e che non era possibile con i metodi disponibili per le stringhe. Però, se questa fosse l'unica nuova risorsa offerta dalle RE, non sarebbe un gran guadagno. Un'altra caratteristica importante è quella di poter specificare parti della RE che devono essere ripetute un certo numero di volte.
Il primo metacarattere che vedremo per esprimere ripetizioni è . L'asterisco * non cerca il carattere ""; serve invece a specificare che il carattere che lo precede può presentarsi zero o più volte e non esclusivamente una sola volta.
Per esempio, ca*t troverà corrispondenza "ct" (0 caratteri "a"), "cat" (1 "a"), "caaat" (3 caratteri "a") e così via. Il motore delle RE ha alcune limitazioni derivanti dalle dimensioni dei tipi int in C, questo vi impedirà di trovare corrispondenze con stringhe con più di 2 miliardi di "a"; ma probabilmente non avete abbastanza memoria per costruire una stringa tanto grande, quindi non dovreste mai raggiungere questo limite.
Ripetizioni come * sono golose; quando si cercano ripetizioni in una RE il motore cerca quella più lunga possibile. Se poi alcune parti del modello non corrispondono, il motore torna indietro e riprova con meno ripetizioni.
Un esempio analizzato passo passo renderà le cose più chiare. Consideriamo l'espressione a[bcd]*b. Questa espressione cerca una stringa che inizia con la lettera "a", prosegue con zero o più lettere della classe [bcd] e termina con "b". Immaginiamo adesso di provare questa RE con la stringa "abcbd".
| Passo | Modello | Spiegazione |
|---|---|---|
| 1 | a | La a nella RE corrisponde. |
| 2 | abcbd | Il motore cerca [bcd]* e va avanti il più possibile, cioè fino alla fine della stringa. |
| 3 | Fallimento | Il motore cerca la b, ma la posizione corrente è alla fine della stringa e quindi fallisce. |
| 4 | abcb | Torna indietro, adesso [bcd]* corrisponde ad un carattere in meno. |
| 5 | Fallimento | Cerca di nuovo b, ma nella posizione corrente trova il carattere "d". |
| 6 | abc | Torna indietro, in questo momento [bcd]* corrisponde solamente con "bc". |
| 6 | abcb | Cerca di nuovo b. Ma stavolta il carattere nella posizione corrente è "b", la ricerca ha successo. |
Il lavoro della RE è terminato e corrisponde con "abcb". Questo mostra come opera l'algoritmo di ricerca, che prima va avanti il più possibile e poi, se non trova la giusta corrispondenza, torna progressivamente indietro riprovando più e più volte. Sarebbe tornato indietro fino a cercare zero corrispondenze con [bcd]* ed al passo successivo avrebbe fallito, concludendo che la stringa non corrisponde per niente alla RE.
Un altro metacarattere per le ripetizioni è +, ed evidenzia una o più occorrenze. È necessario fare attenzione alla differenza tra * e +; * cerca zero o più occorrenze, quindi tutto quello che può essere ripetuto può anche essere del tutto assente, mentre con + è necessaria almeno una occorrenza. Per usare un esempio simile al precedente, ca+t troverà "cat" (1 "a"), "caaat" (3 "a"), ma non troverà "ct".
Esistono altri due qualificatori di ripetizioni. Il carattere punto interrogativo, ?, cerca una o zero ripetizioni; potete pensarlo come un marcatore per qualcosa che è facoltativo. Ad esempio, home-?brew troverà sia "homebrew" che "home-brew".
Il qualificatore di ripetizioni più complicato è {m,n}, dove m e n sono numeri decimali interi. Significa che devono esserci almeno m ripetizioni e non più di n. Ad esempio a/{1,3}b corrisponderà con "a/b", "a//b" e "a///b". Però non troverà "ab", che non ha barre, o "a////b", che ne ha quattro.
È possibile omettere m o n; nel caso viene assunto un valore ragionevole al posto di quello mancante. L'omissione di m viene interpretata come un limite inferiore posto a 0, mentre l'omissione di n mette il limite superiore a infinito, o meglio, al limite di 2 miliardi menzionato in precedenza, che possiamo considerare infinito.
Lettori con un'inclinazione riduzionista potrebbero notare che i primi tre qualificatori potrebbero essere espressi usando questa notazione. {0,} equivale a *, {1,} equivale a + e {0,1} equivale a ?. Però è meglio usare *, + e ? quando possibile, semplicemente perché sono più compatti e più facili da leggere.
Struttura di <regex>
L'implementazione delle espressioni regolari in C++ è costituita principalmente da 3 funzioni (in particolare sono template di funzioni) per l'esecuzione delle tre più comuni operazioni con le espressioni regolari:
- matching (regexmatch)
- ricerca (regexsearch)
- sostituzione (regexreplace)
Parleremo con sufficiente dettaglio di queste funzioni negli esempi successivi.
- basicregex, una classe per memorizzare e definire un'espressione regolare. Questa classe può a sua volta essere istanziata come regex (espressioni regolari su stringhe) oppure come wregex (espressioni regolari per stringhe wide).
- matchresult, una classe per memorizzare i risultati di una ricerca o di un matching. .
- regexerror, classe per la gestione delle eccezioni.
- regexiterator, classe per gestire l'iterazione fra le diverse strutture identificate in una stringa.
Infine il namespace regexconstants che contiene tutta una serie di costanti e bitmask per passare parametri alle funzioni del modulo regex.
Iteratore
Sia il codice seguente
#include <iostream> #include <regex> #include <string> int main() { std::string testo = "Ciao, 12345 Mondo!"; // Pattern di espressione regolare per corrispondere ai caratteri alfabetici std::regex pattern("[a-zA-Z]+"); // Oggetti iterator per iterare sulle corrispondenze std::sregex_iterator iteratore(testo.begin(), testo.end(), pattern); std::sregex_iterator fineIteratore; // Iterare sulle corrispondenze while (iteratore != fineIteratore) { std::smatch corrispondenza = *iteratore; std::string parola = corrispondenza.str(); std::cout << parola << std::endl; ++iteratore; } return 0; }
In questo esempio, definiamo una stringa testo contenente il testo da analizzare. Poi, definiamo un pattern di espressione regolare [a-zA-Z]+ che corrisponde a una o più lettere alfabetiche. Creiamo un oggetto iteratore utilizzando std::sregexiterator per iterare sulle corrispondenze trovate nel testo utilizzando il pattern. L'oggetto fineIteratore rappresenta l'iteratore di fine per segnalare la fine delle corrispondenze. All'interno del ciclo while, otteniamo ogni corrispondenza utilizzando l'operatore dereferenziazione *iteratore, quindi otteniamo la stringa corrispondente utilizzando il metodo str() dell'oggetto corrispondenza. Infine, stampiamo la parola corrispondente e incrementiamo l'iteratore.
In questo modo, puoi iterare sulle corrispondenze trovate nella stringa utilizzando le espressioni regolari in C++.